We saw this live in the AI Money Group: Anthropic announced that Claude subscriptions will no longer cover OpenClaw usage starting Apr 4. You can still use Claude through OpenClaw, but now it’s pay-as-you-go. This is not just a billing line item — it’s a model-control line in the sand.
The email was explicit: subscription credits for OpenClaw usage are now separate from baseline Claude products.
Anthropic is keeping value inside its own products while charging for third-party orchestration routes.
Users got 24-hour notice. If your stack is built on that model assumption, that is a real operational event.
From a founder lens, this feels like walled-garden logic and an ecosystem tax at the exact moment we are asking people to own their own systems.
If you assumed “subscription = done,” this one line breaks that equation overnight.
This is a strategic boundary: hosted AI and machine-access tools can be treated as separate lanes.
Those with OpenRouter failover and model diversification keep moving. Others suddenly have blockers.
If a single source can flip overnight, your operations should not hinge on that one source alone.
As much as I respect Anthropic’s business model evolution, this move reveals the downside of using a provider’s subscription as your core operating budget.
For a lot of users, “it works under subscription” becomes “I can’t run what I was promising” the day a billing rule changes.
The message is clear: if you want scale with tools like OpenClaw, own the stack you connect to, not just the monthly checkbox.
This one update is not about whether OpenClaw is useful. It’s about whether your implementation can absorb change without operational panic.
In plain English: this is a wake-up call for everyone building long-term systems.
Today it is Claude. Yesterday it was another model. Tomorrow it could be a different API condition. You do not need to be paranoid; you just need redundancy.
We saw 24-hour notice in practice. If your business operations include AI Agents, your stack design should expect that pace of change.
It’s not about choosing one favorite model. It’s about making one favorite model not the only one your system depends on.
Subscriptions are comfort. Infrastructure is reliability. If you confuse the two, your AI operations become expensive emotionally and financially.
Here’s what I’m actually seeing work better with groups trying to stay both reliable and fast:
For teams running AI every day, I recommend the $200/month ChatGPT tier as a stable default. In practice, GPT-5.3 Spark should be the first model I lean on for routine work.
When the task needs more depth, more reasoning, or a harder edge, I use GPT-5.4 instead of forcing one model to do everything all day.
Even if we don’t let platform billing decisions drive our stack, we can still use Claude where it’s strongest: installed on the computer, then taught as a tool route inside OpenClaw.
That command pattern is useful for build-heavy work when OpenClaw should ask a local Claude session to do heavier file tasks.
Attached screenshot context comes directly from the update chain. I use these kinds of references to keep the framing honest and practical.
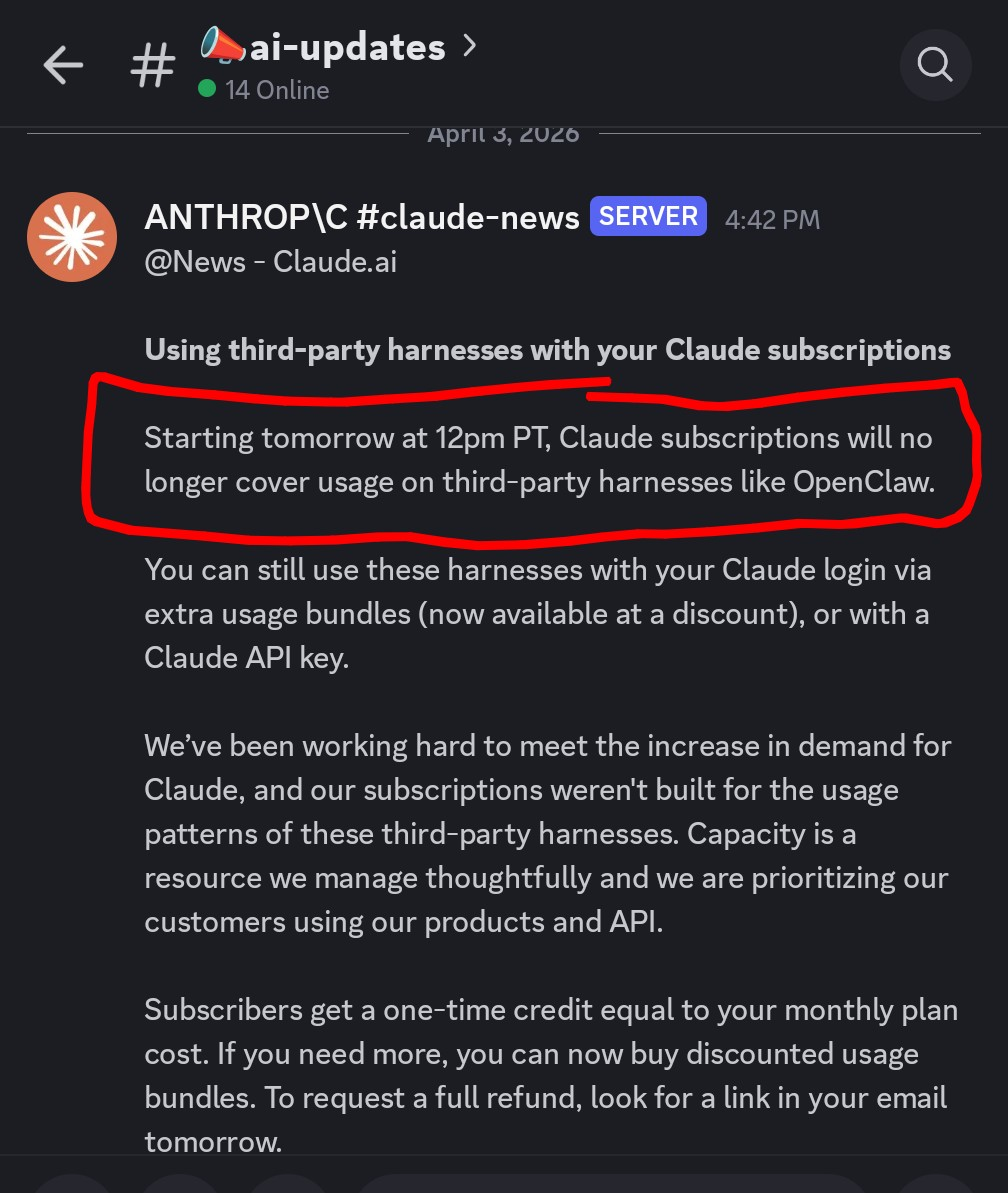
Email/notification style evidence showing the date and rule update. It’s a reminder that these changes can land quickly.
Operationally, we should assume the platform can restrict an access path with notice and that our job is to keep the business productive anyway.
The fix is system design, not outrage.
For people serious about getting consistent results with AI: build this order into your system.
Use OpenRouter (or equivalent orchestration) so model swaps are part of the default operating flow, not a rescue plan.
Document exactly what flips when Model A becomes unavailable, including alert, failback, and message templates.
If your use case needs continuity, open-source models and your own server layer reduce the blast radius of vendor policy change.
It means stop confusing one billing stream with your whole operating model.
Even with strong tools, the real advantage comes from how resilient your operating process is, not how much power one model alone can claim.
In short: don’t outsource your resilience.
“Don’t build your future on a tool that can be repriced or rerouted while your business is in motion.”
That is the clean version of this page. If your stack can’t absorb a change this fast, you don’t build speed first — you build redundancy first.
The email from Anthropic may be annoying. It can also be useful — a reminder to stop treating one model provider as “the platform” and start treating your system as an actual platform.

Beau turns live operational moments into short, practical strategy pages: what changed, why it matters, and what to do next so teams can keep shipping while platforms shift.