VA Staffer made a deliberate decision to invest in premium on-site infrastructure for Managed AI Employees — with Proxmox clustering, Ceph storage, VLAN-separated networking, high-availability failover, and local-model capability through NVIDIA DGX Spark. This page shows what we bought, why we bought it, and why it matters to the clients trusting us with their business operations.
The original page explained the architecture. This update shows the completed physical install, a live performance walkthrough from Jeff, and final photos from the deployed rack.



This wasn’t a cheap shortcut. It was a strategic decision to trade upfront capital for long-term control, better performance, stronger security, and the kind of infrastructure story serious buyers can actually trust.
3-node cluster, 10 GbE switching, DAC cables, and NVIDIA DGX Spark.
Approximate Phase 1 support at 8 GB RAM each with HA headroom.
Expected AI Employee count after expanding Stack 1 to 5 nodes.
No noisy-neighbor VPS layer and no third-party provider physical access.
Identical compact server nodes using AMD Ryzen 9 9955HX processors with 96 GB DDR5 RAM each.
Ceph usable capacity at replication factor 3 with one 2 TB OSD per node and a clean path to ~4 TB after OSD 2 expansion.
SFP+ managed switching with VLAN-separated management, internet, and Ceph traffic across tagged trunks.
NVIDIA GB10 Grace Blackwell–based system for local model inference when clients need maximum control and zero cloud exposure.
This is the heart of the stack: a Proxmox VE hyperconverged cluster for orchestration and storage, a dedicated 10 GbE fabric for clean traffic separation, and a DGX Spark layer for fast local AI inference.
Upstream internet connectivity for client traffic, messaging channels, and external service access.
128 GB unified memory, 4 TB NVMe, 200 Gbps networking, and local-model inference when cloud exposure is not acceptable.
Lose a drive or a node and the cluster keeps moving. That is the design brief, not a happy accident.
No noisy-neighbor VPS layer. Every CPU cycle and RAM allocation belongs to the workload running on this hardware.
Data, memory, configs, and client workflows live on hardware VA Staffer owns and controls directly.
Managed AI Employees live inside their own dedicated environments and can operate in the messaging channels clients already use.
Every piece of data is replicated across three physical machines, which means a node failure does not equal client data loss.
If a node goes down, AI Employees can restart on surviving nodes within roughly 60–90 seconds instead of waiting on a hosting provider incident.
The DGX Spark handles local inference when clients need privacy-first deployments or want to reduce dependency on external cloud model APIs.
Adding storage, adding nodes, and eventually launching Stack 2 all follow the same clean, repeatable pattern.
This is real hardware with real numbers behind it. The point is not to look expensive. The point is to be capable, reliable, and scalable from day one.
| Component | Specification | Why It Matters |
|---|---|---|
| 3× Compact Server Nodes | AMD Ryzen 9 9955HX, 96 GB DDR5-5600, included 2 TB NVMe | Identical hardware enables live migration, predictable HA behavior, and consistent AI Employee performance. |
| OS Drive Per Node | 256 GB NVMe in Slot 3 | Keeps Proxmox isolated from Ceph data storage and leaves the included 2 TB SSD dedicated to OSD duty. |
| Ceph Expansion Path | Slot 2 reserved for future 2 TB NVMe on every node | Lets VA Staffer double usable storage with zero downtime when client demand reaches the trigger point. |
| Networking Fabric | 12-port 10 GbE SFP+ managed switch + DAC cables | Separates management, internet, and Ceph traffic cleanly while leaving expansion ports available. |
| Local Inference Layer | NVIDIA DGX Spark, 128 GB unified memory, 4 TB NVMe | Supports privacy-sensitive local-model execution when clients do not want data passing through external APIs. |
| Total Phase 1 Investment | $11,535 | Signals long-term commitment and creates a more durable margin structure than renting equivalent capacity forever. |
This is the section most buyers care about, even if they don’t ask it out loud. Where does my AI live, who controls it, and how seriously did you build this?
We built for redundancy first, not cost minimization.
That single decision changes the character of the entire offer. It means your AI Employee is meant to keep working even when hardware fails, nodes reboot, or infrastructure is under pressure.
The current 3-node cluster is the starting line, not the ceiling. Storage and compute can expand independently, which gives VA Staffer a clean path to grow with client demand instead of overbuilding too early.
Launch with one 2 TB OSD per node, Ceph replication factor 3, and roughly ~2 TB usable storage at launch.
Add OSD 2 drives to all three nodes for about $420 total and expand usable Ceph storage from ~2 TB to ~4 TB with zero downtime.
Add Node 4 plus OSD 2. Capacity jumps toward 44 AI Employees while fault tolerance and storage distribution improve.
Add Node 5 plus OSD 2. Stack 1 reaches about 55 AI Employees and ~6.7 TB usable storage.
Launch Stack 2 as a fresh 3-node cluster and repeat the same pattern without disturbing the original pool.
80 cores / 160 threads, 480 GB DDR5 RAM, 20 TB raw Ceph storage, ~6.7 TB usable at rep=3, and about 55 AI Employees.
Matching CPUs keep live migration simple and reliable. No compatibility gymnastics, no restart penalties just to move workloads safely.
The hardware is impressive, sure — but the real point is what it changes for the business owner using a Managed AI Employee every day.
Your AI Employee is not fighting with random neighboring workloads on a shared cloud host. Response quality stays more consistent when compute is dedicated.
Memory, workflows, and configurations live on hardware VA Staffer controls directly rather than a generic shared-tenancy VPS environment.
Drive dies? Node reboots? The stack is designed to absorb that quietly instead of turning a client’s business workflow into downtime drama.
There’s already a roadmap for how capacity scales from 3 nodes to 5, then to Stack 2. That matters when buyers want confidence, not hand-waving.
For sensitive workflows, VA Staffer can increasingly support privacy-first local inference instead of forcing everything through third-party model APIs.
This tells clients they are not buying “ChatGPT with a wrapper.” They are buying a managed operational system with real infrastructure underneath it.
Your AI Employee should not feel like an experiment. It should feel like a serious business asset.
That is the story this infrastructure tells: premium intent, operational discipline, and a stack built to support real client work instead of demo-day theater.
This page was built from VA Staffer’s March 2026 infrastructure summary and growth plan.
Founder & CEO, VA Staffer. The strategy, positioning, and buyer narrative behind this infrastructure investment come directly from the way VA Staffer intends to deliver Managed AI Employees.
Brandon, Developer & Network Engineer at Belew Consulting. Technical design includes the Proxmox cluster, Ceph storage architecture, networking plan, and expansion path.
The full March 2026 report now lives directly on this page as a polished embedded appendix using the prepared markdown and supporting visuals, so readers can go deep without leaving the site.
A real on-site stack built for Managed AI Employees, not a rented cloud placeholder.
High-availability clustering and Ceph replication were treated as baseline requirements.
The report now breaks out where storage, nodes, and capacity expand as client demand grows.
VA Staffer · March 2026
Authored by: Jeff J Hunter, Founder & CEO, VA Staffer Infrastructure design & implementation: Brandon, Developer & Network Engineer, Belew Consulting
VA Staffer has made a deliberate, strategic decision to build and operate its own on-premise server infrastructure rather than rely on third-party VPS hosting providers. This document summarizes the hardware purchased, the reasoning behind that decision, and our planned path to expand capacity as we grow our client base. This is premium, enterprise-class hardware — the price reflects that, and that is exactly the point.
At the core of this infrastructure is a Proxmox VE hyperconverged cluster — a proven enterprise-grade virtualization platform used by organizations worldwide. This cluster serves as the dedicated compute and storage backbone for our Managed AI Employee service, powered by OpenClaw, which delivers role-specific AI automation directly inside our clients' businesses via the communication tools they already use every day.
What is a Managed AI Employee? >
VA Staffer's Managed AI Employee service gives business owners a role-specific AI that lives inside WhatsApp, Telegram, Slack, or the messaging tools they already use — and actually does things. Not a chatbot. A configured, always-on digital worker built around a specific role in your business: research, documentation, summaries, client follow-up, first drafts, internal Q&A, and more. Built on OpenClaw — the open-source AI agent platform with over 247,000 GitHub stars — and delivered as a fully managed service by Jeff J Hunter and the VA Staffer team. We build it, configure it, and help you improve it so it becomes a real business asset, not more tech clutter.
We purchased three identical compact server node units, each configured as a full cluster node. Identical hardware across all nodes is a hard requirement for Proxmox live migration — AI Employees can move between nodes in real time without downtime only when the underlying CPUs match exactly.
| Component | Specification |
|---|---|
| Form factor | Compact server node (mini PC class, fanless-capable) |
| CPU | AMD Ryzen 9 9955HX: 16 cores / 32 threads, Zen 5 architecture |
| RAM | 96 GB DDR5-5600 MHz (dual-channel, included) |
| Included SSD | 2 TB M.2 PCIe 4.0 NVMe, Ceph OSD 1 (Slot 1) |
| OS Drive | 256 GB M.2 PCIe 4.0 NVMe, Slot 3, purchased separately (~$25 each) |
| Ceph OSD 2 | Not installed at launch — Slot 2 reserved for future 2TB NVMe expansion |
| Network | Dual 10 Gbps SFP+ LAN + 2.5G RJ45 + Wi-Fi 6E |
| Expansion | Built-in PCIe x16 slot (supports split), for future GPU or NIC |
| NVMe Slots | 3× M.2 PCIe 4.0 slots, all three available |
| Unit Price | $2,079.00 per unit |
Each node launches with one Ceph OSD drive — the included 2 TB SSD in Slot 1. A dedicated 256 GB NVMe in Slot 3 handles the OS and Proxmox installation and nothing else. Slot 2 on every node is intentionally left empty at launch and reserved for a second 2 TB NVMe when storage demand requires it. Adding OSD 2 drives to all three nodes costs ~$420 and can be done with zero downtime — Ceph rebalances automatically. This gives us a clean, cost-efficient starting point with a clear storage expansion path as AI Employee deployments grow.
| Slot | Purpose |
|---|---|
| Slot 3 (PCIe 4.0) | 256 GB NVMe: Proxmox OS and boot drive |
| Slot 1 (PCIe 4.0) | 2 TB NVMe: Ceph OSD 1 (included with unit) |
| Slot 2 (PCIe 4.0) | Empty: reserved for 2TB NVMe OSD 2, added when storage demands it |
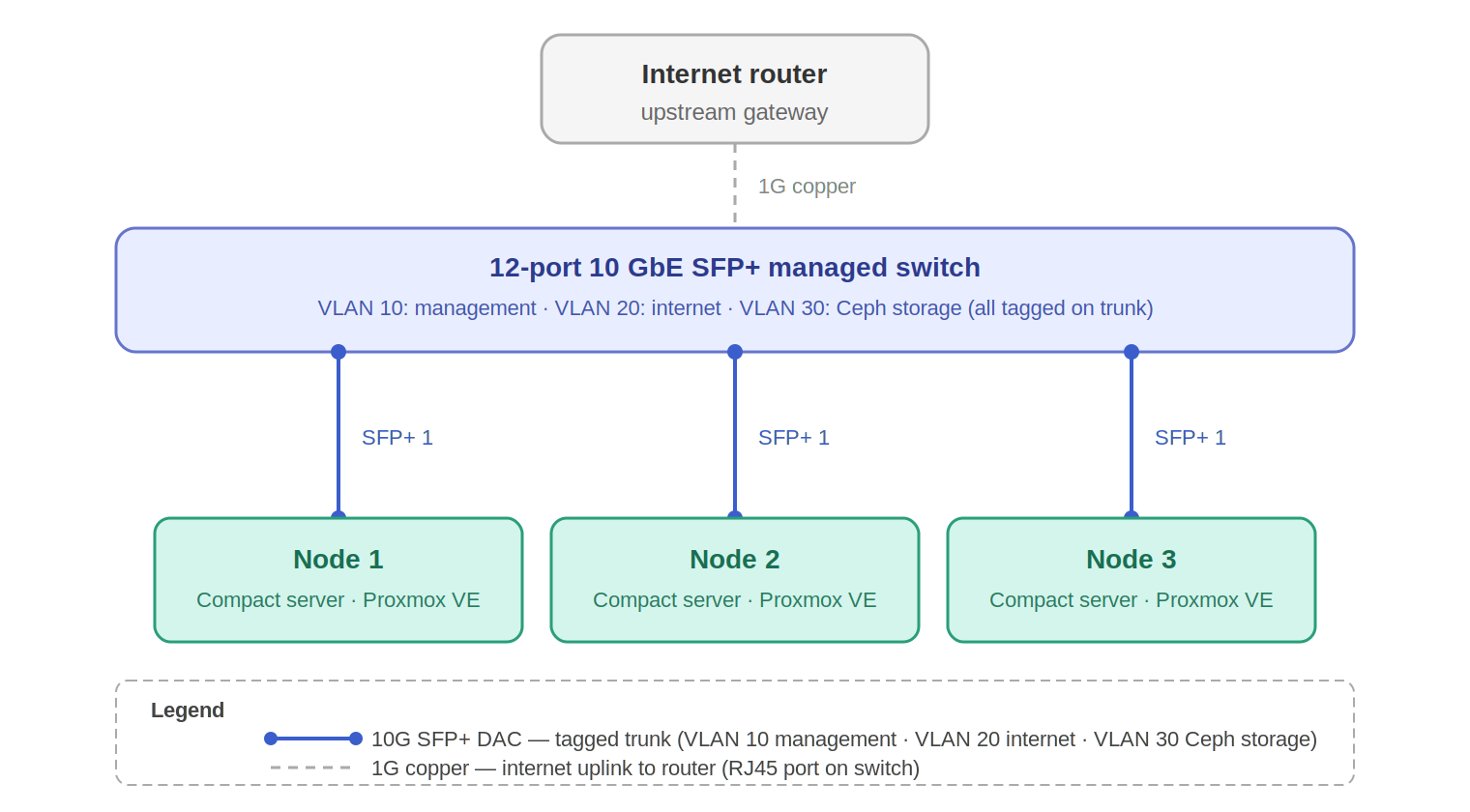
All cluster networking runs through a single 12-port 10 GbE SFP+ managed switch. Each node connects via one SFP+ DAC cable carrying a tagged VLAN trunk — no separate management switch required. Three VLANs are trunked over that single connection per node:
| Component | Specification |
|---|---|
| Switch | 12-port 10 GbE SFP+ managed switch |
| Node connection | 1× SFP+ DAC cable per node (tagged trunk) |
| VLAN 10 | Management: Proxmox web UI, SSH, cluster heartbeat |
| VLAN 20 | Internet: AI Employee traffic and external connectivity |
| VLAN 30 | Ceph storage: OSD replication traffic, isolated |
| Internet uplink | 1G copper RJ45 to upstream router / gateway |
| DAC cables | 3× 0.5m SFP+ passive DAC (one per node, 9 ports remain for expansion) |
A deliberate design decision runs through every layer of this infrastructure: we built for redundancy first, not cost minimization. It would have been straightforward to deploy a single Ceph OSD per node, a single VLAN, or fewer nodes — and the upfront cost would have been lower. We chose not to do that.
Every client whose AI Employee runs on this infrastructure is depending on it. If a drive fails, a node goes offline, or a switch port dies, the cluster should keep running without missing a beat. Proxmox HA automatically restarts AI Employees on surviving nodes. Ceph replication factor 3 means every piece of data exists on three separate physical machines simultaneously — losing one node or one drive does not lose a single byte of client data. The 10 GbE network is fast enough that Ceph replication and AI Employee traffic never compete in a way that degrades performance.
What redundancy means for clients >
Your AI Employee does not go down because a hard drive failed or a server needed a reboot. The infrastructure is designed to absorb failures silently — the kind of resilience that would require enterprise-grade cloud SLAs to approximate, and that we have built into the physical layer of our own stack.
Alongside the Proxmox cluster, VA Staffer operates an NVIDIA DGX Spark — a purpose-built AI supercomputer designed specifically for local large language model inference. This is existing hardware already in our stack, not a future purchase. Where the Proxmox cluster manages AI Employee runtime, networking, and storage, the DGX Spark handles one job: running AI models locally at full speed, with nothing sent to any external cloud API.
| Component | Specification |
|---|---|
| Unit | NVIDIA DGX Spark |
| Superchip | NVIDIA GB10 Grace Blackwell, 1 petaFLOP FP4 AI performance |
| Unified memory | 128 GB LPDDR5X, unified CPU + GPU memory pool |
| Storage | 4 TB NVMe SSD |
| Networking | 200 Gbps QSFP ports (ConnectX-7 NIC), supports multi-unit clustering |
| Node scaling | Two units can be linked via 200 Gbps to run models up to 405 billion parameters |
| AI software | NVIDIA AI stack preinstalled: NIM, frameworks, libraries, pre-trained models |
| Role in stack | Local LLM inference engine: AI Employees run on-site models when required |
| Current price | $4,699 (raised from $3,999 in February 2026 due to memory supply constraints) |
| Item | Qty | Cost |
|---|---|---|
| 3× compact server node (AMD Ryzen 9 9955HX, 96GB RAM, 2TB SSD) | 3 | $6,237.00 |
| 3× 256 GB M.2 PCIe 4.0 NVMe (OS drives) | 3 | $75.00 |
| 12-port 10 GbE SFP+ managed switch | 1 | $500.00 |
| SFP+ passive DAC cables (0.5m) | 3 | $24.00 |
| NVIDIA DGX Spark (128GB unified memory, 4TB, 200Gbps) | 1 | $4,699.00 |
| Total Infrastructure Investment (Phase 1) | $11,535.00 |
This was one of the most deliberate decisions Jeff J Hunter and Brandon at Belew Consulting made during the planning phase. The question was straightforward: do we run our Managed AI Employee service on rented cloud infrastructure from providers like AWS, DigitalOcean, Linode, or Vultr — or do we own and operate the hardware ourselves?
We chose an on-site build. Here is why — and why it matters directly for every client whose AI Employee runs on this infrastructure.
Honest acknowledgment >
We are not going to pretend this is the cheaper short-term option. On-site enterprise hardware is expensive — that is the reality. Major hosting brands like DigitalOcean, Linode, and Vultr could have us running in an hour for less upfront. The on-site investment is a deliberate trade of capital for long-term control, performance, and client trust. Combined with the NVIDIA DGX Spark at $4,699, our Phase 1 infrastructure represents over $11,600 in hardware. Yes — it costs significantly more to start. It is absolutely worth it for the clients we serve and the standard of service we intend to deliver.
AI Employees built through VA Staffer's Managed AI Employee service process sensitive client business data — customer records, communications, internal workflows, SOPs, lead data, and in some cases financial or healthcare-adjacent information. When that data lives on a major cloud provider's shared infrastructure, it is subject to:
On our hardware, data never leaves a physical location we control. We determine who has access, how it is encrypted, and what the retention policy is. This is not a feature we can replicate on any VPS plan at any price — it is a function of physical ownership.
For our clients, this means the AI Employee we build for their business — its memory, its configurations, their customer data, and their workflows — are stored on dedicated hardware that belongs to VA Staffer. Not co-mingled in a shared pool managed by a corporation with its own interests.
Cloud VPS instances share underlying physical hardware with dozens or hundreds of other customers. During peak demand on that shared host, your workload slows down — a phenomenon known as the "noisy neighbor" problem. AI inference workloads are particularly sensitive to this: a 200ms latency spike on a shared host becomes a noticeably sluggish AI Employee response for a client's customer.
Each of our nodes has 16 dedicated CPU cores, 96 GB of dedicated RAM, and PCIe 4.0 NVMe storage that no other customer shares. The AMD Ryzen 9 9955HX is a Zen 5 architecture chip — the same generation as AMD's current desktop flagship line — delivering consistent and predictable performance that VPS hosting simply cannot guarantee.
VPS pricing scales linearly and indefinitely upward. The more clients we onboard, the more we pay — forever, with no ceiling and no equity. With owned hardware, adding capacity means purchasing additional nodes and slotting them into an infrastructure we already own and understand.
Our current 3-node cluster can run approximately 33 AI Employees at 8 GB RAM each. Adding two more nodes brings that to 55 AI Employees with significantly improved fault tolerance — and the incremental hardware cost is the same per-node price, not an escalating monthly subscription.
On our own infrastructure we can:
In short: on our hardware, every configuration decision is ours to make. No support tickets. No feature request queues. No provider deprecating a service we depend on.
At equivalent VPS capacity (96 vCPUs, 288 GB RAM, ~4 TB usable storage), major providers charge roughly $1,200–$2,500 per month. Our Phase 1 cluster hardware investment breaks even against those VPS costs within 3–6 months. Every month after that, the infrastructure serves our clients at zero incremental hosting cost — every dollar of margin stays in the business rather than going to a cloud provider.
The bottom line for every VA Staffer client >
Your AI Employee — built by Jeff J Hunter and the VA Staffer team on OpenClaw — runs on dedicated hardware we own and operate, with no shared tenancy and no third-party data access. This means faster response times, genuine data security, and an AI Employee that stays reliable as your business grows. That is something a shared VPS hosting account cannot give you at any price — and it is exactly why we made this investment.
| Metric | Value |
|---|---|
| Nodes | 3 × compact server node |
| Total CPU cores / threads | 48 cores / 96 threads (AMD Ryzen 9 9955HX) |
| Total RAM | 288 GB DDR5-5600 MHz |
| Usable RAM (after overhead) | ~270 GB |
| Ceph raw storage | 6 TB (1× 2TB OSD × 3 nodes, at launch) |
| Ceph usable (rep=3) | ~2 TB at launch, ~4 TB after OSD 2 expansion |
| Max AI Employees (8 GB RAM each) | ~33 |
| Ceph OSDs per node | 1× 2TB NVMe at launch. Slot 2 reserved for second OSD |
| Network fabric | 10 GbE SFP+ tagged trunk (management, internet, Ceph on separate VLANs) |
| Quorum fault tolerance | 1 node (cluster survives 1 failure) |
| HA failover | AI Employees restart on surviving nodes within ~60–90 seconds |
| Proxmox version | Proxmox VE 8.x |
| Storage backend | Ceph RBD (hyperconverged, rep=3) |
Each Proxmox stack has a maximum of 5 nodes. Storage grows linearly as we add nodes within Stack 1. When Stack 1 is complete, Stack 2 begins as a fresh cluster — it does not extend Stack 1's Ceph pool. Each stack has its own independent storage:
| Stack 1 nodes | Raw storage | Usable (rep=3) | Notes |
|---|---|---|---|
| 3 nodes | 12 TB | ~4 TB | Phase 1 (current) |
| 4 nodes | 16 TB | ~5.3 TB | Phase 2 interim |
| 5 nodes | 20 TB | ~6.7 TB | Phase 2 complete: Stack 1 at max capacity |
Ceph rebalances data automatically as each new node joins — no manual migration, no downtime, no intervention required.
The 3-node cluster is a deliberate starting point, not a ceiling. The Proxmox and Ceph architecture we have deployed is designed from the ground up to expand by adding nodes — no reconfiguration, no downtime, no data migration required.
Our target trigger points are:
Each AI Employee runs in its own dedicated environment with 8 GB RAM, 2 vCPU, and 100 GB of Ceph RBD disk storage.
Expanding a Proxmox + Ceph cluster is intentionally straightforward:
1. Rack and cable the new compact server node — plug into the 10 GbE managed switch SFP+ ports (9 ports remain available)
2. Install Proxmox VE 8.x, assign static IP per the existing address plan
3. Run pvecm add <pve01-ip> — the node joins the cluster in under a minute
4. Install Ceph, create OSDs — Ceph automatically rebalances data across all nodes in the background
5. Add new node to the HA group — AI Employees can now migrate to it immediately
The entire process takes under an hour. No existing AI Employees are interrupted. No data is moved manually. The cluster simply gets larger.
One of the most important design advantages of this infrastructure is that storage and compute are completely independent expansion levers. You do not need to add a node to get more storage, and adding a node automatically brings more AI Employee capacity without needing a new storage drive. The diagram below maps the recommended upgrade path from today through Stack 1 at full build-out, driven entirely by active AI Employee count.
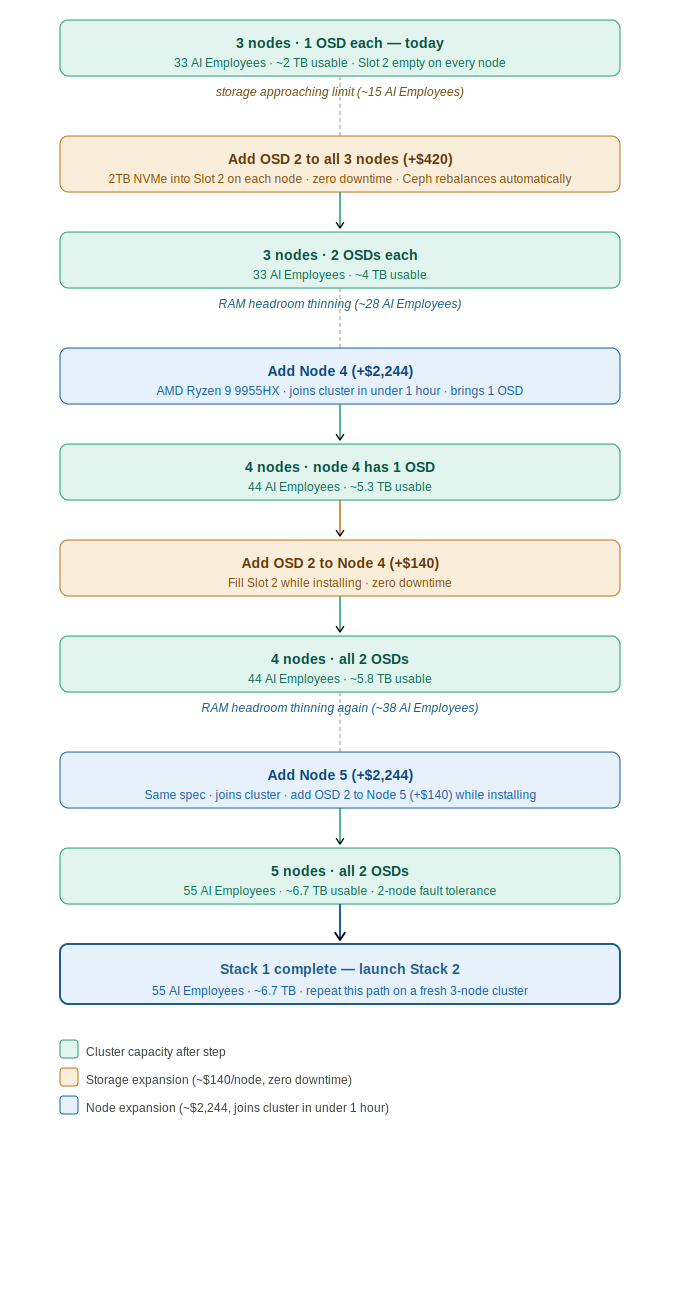
The amber steps are pure storage expansions — a 2TB NVMe drive dropped into Slot 2 of each node at ~$140 each, with zero downtime. The blue steps are compute expansions — a new node joins the cluster in under an hour and immediately adds 11 AI Employee slots. Each expansion is triggered by a specific AI Employee count threshold, not by a calendar or budget cycle.
All current and future nodes will be the same compact server node with the AMD Ryzen 9 9955HX. This is not an aesthetic preference — it is a technical requirement. Proxmox live migration requires that the destination CPU supports every instruction the source CPU exposes to the AI Employee. Identical CPUs guarantee this without compatibility flags or restarts.
The 10 GbE managed switch has 12 SFP+ ports — we are currently using 3 (one per node), leaving 9 ports available for the remaining 2 Stack 1 nodes plus all future Stack 2 nodes.
| Metric | Value |
|---|---|
| Additional nodes | 2× compact server node (same spec as Phase 1) |
| Phase 2 hardware cost | ~$4,208 (2× $2,079 unit + 2× $25 OS NVMe) |
| OSD 2 expansion (all 5 nodes) | ~$700 (5× $140) — add any time storage demands it |
| Total cluster investment (fully built out) | ~$16,903 (excl. DGX Spark) |
| Total cores / threads | 80 cores / 160 threads |
| Total RAM | 480 GB DDR5 |
| Ceph usable (rep=3, all OSDs) | ~6.7 TB |
| Max AI Employees (8 GB RAM each) | ~55 |
| Quorum fault tolerance | 2 nodes (lose any 2, cluster stays fully operational) |
| HA headroom | Comfortable — 1 node failure redistributes AI Employees across 4 survivors |
The hardware selection was not made lightly. We originally scoped this build around a competing platform built around the Intel i9-12900H and 64 GB of RAM — a capable machine, but one we ultimately felt left too little headroom for the workloads our AI Employees need to execute. We made a conscious decision to step up to the AMD Ryzen 9 9955HX — AMD's latest Zen 5 architecture — with 96 GB of DDR5-5600 MHz RAM per node. The goal was simple: give our AI Employees plenty of speed and memory to execute without constraint. When you are running always-on agents that handle research, documentation, client communication, and multi-step workflows simultaneously, headroom is not optional — it is the product.
As AI models continue to improve, a growing number of clients — including Jeff J Hunter personally — will want their AI Employee to run entirely on local models. Not because cloud models like Claude or GPT-4o are not powerful, but because some clients have data that should never leave their environment. Healthcare-adjacent workflows, sensitive business strategy, proprietary client data, and internal communications are examples where sending information to a third-party cloud API is simply not acceptable.
The NVIDIA DGX Spark makes this possible. An AI Employee running on a local model via the NVIDIA DGX Spark sends nothing to OpenAI, Anthropic, or any other external provider. The model runs on hardware inside our facility, inference happens locally, and the client's data never touches the internet. This is not a feature most managed AI services can offer at any price. We can offer it because we own the infrastructure that makes it possible.
What this means for clients >
If you are a VA Staffer client who needs complete data privacy — whether for regulatory reasons, competitive sensitivity, or personal preference — your AI Employee can be configured to run on a local model via the NVIDIA DGX Spark. Nothing leaves our facility. No cloud API calls. No third-party data exposure. Just your AI Employee, running on dedicated hardware, processing your information in complete isolation.
VA Staffer's growth model is built around stacks, not individual nodes. Each stack is a self-contained 3-to-5 node Proxmox cluster with its own Ceph storage pool and quorum. Stack 1 — our current cluster — grows from 3 to 5 nodes in Phase 2. When Stack 1 reaches capacity, we launch Stack 2: a fresh 3-node cluster that expands to 5 nodes alongside Stack 1. Two full stacks support 110 AI Employees with 13.3 TB of usable storage. At that scale, we will evaluate moving the infrastructure into a dedicated managed server facility for additional power redundancy, physical security, and enterprise-grade network uptime.
This approach also means each stack is independently resilient. A failure in Stack 1 does not affect Stack 2, and clients can be distributed across stacks for maximum isolation.
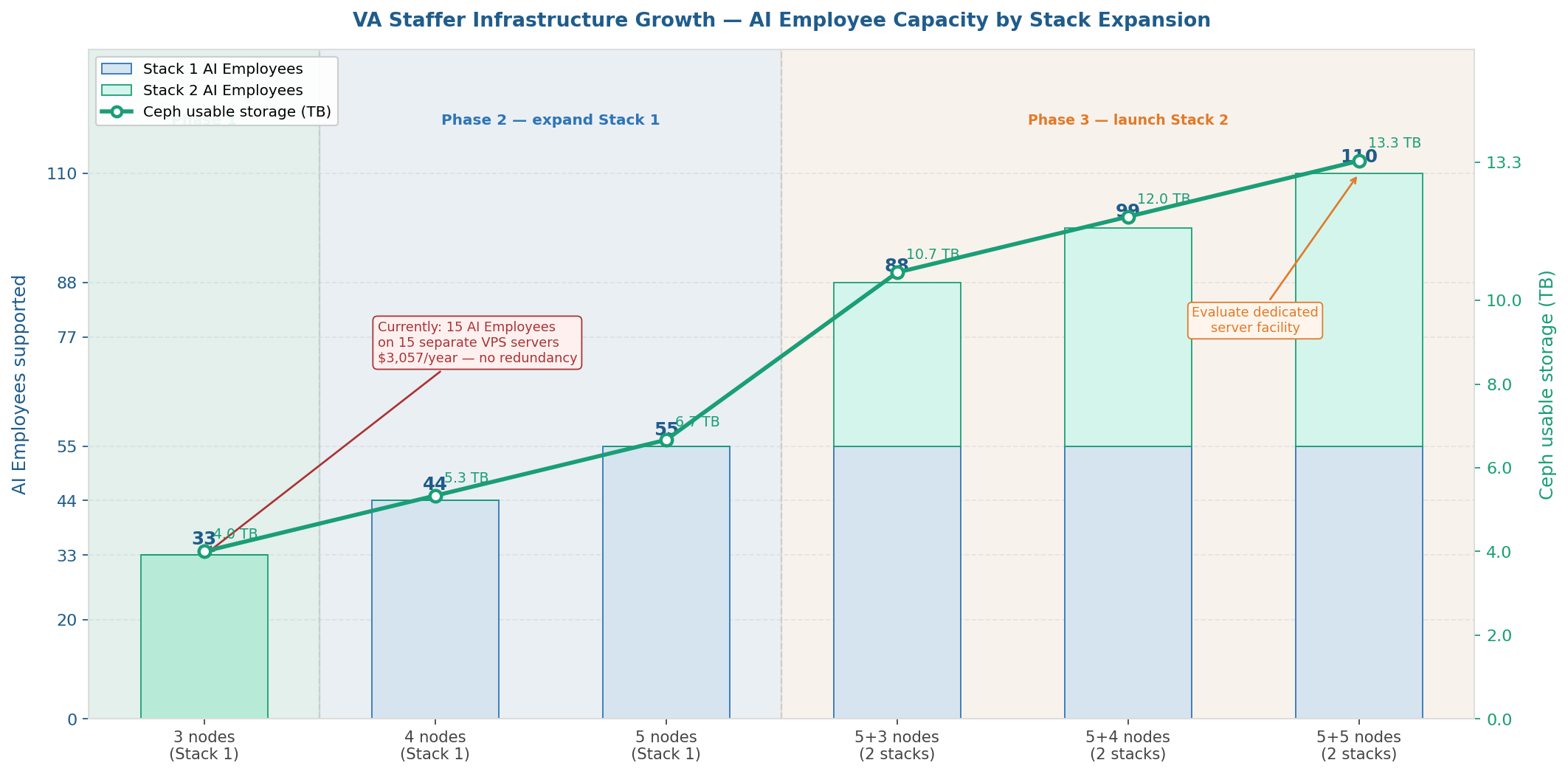
| Configuration | AI Employees | Ceph usable | Phase | Notes |
|---|---|---|---|---|
| Stack 1: 3 nodes (1 OSD each) | 33 | ~2 TB | Phase 1 | Current — Slot 2 reserved for OSD 2 |
| Stack 1: 3 nodes + OSD 2 | 33 | ~4 TB | Phase 1 | Add OSD 2 to all 3 nodes (+$420) |
| Stack 1: 4 nodes | 44 | ~5.3 TB | Phase 2 | First expansion node added |
| Stack 1: 5 nodes | 55 | ~6.7 TB | Phase 2 | Stack 1 complete — 2-node fault tolerance |
| Stack 1+2: 5+3 nodes | 88 | ~10.7 TB | Phase 3 | Stack 2 launched at 3 nodes |
| Stack 1+2: 5+4 nodes | 99 | ~12 TB | Phase 3 | Stack 2 expanding |
| Stack 1+2: 5+5 nodes | 110 | ~13.3 TB | Phase 3 | Evaluate dedicated server facility |
Before building this infrastructure, VA Staffer ran its first 15 AI Employees on individual VPS servers — one server per AI Employee. Those servers each provided 2 vCPU cores, 8 GB RAM, and 100 GB NVMe storage at $203.88 per year. For getting started, that approach worked. But as we grew, the limitations became clear.
| Metric | VPS reality |
|---|---|
| VPS per AI Employee | 2 vCPU cores · 8 GB RAM · 100 GB NVMe |
| Annual cost per VPS | $203.88/year |
| 15 AI Employees on VPS | $3,057.60/year — and growing linearly with every new client |
| Redundancy | None — if the VPS goes down, the AI Employee goes down |
| HA failover | None — no automatic restart, no cluster heartbeat |
| Data protection | Shared infrastructure — no Ceph replication, no rep=3 safety net |
| Compute headroom | Zero — each VPS is exactly sized, no burst capacity |
| Storage | 100 GB per AI Employee — isolated, not pooled |
Our current 3-node cluster provides 48 dedicated CPU cores, 288 GB of RAM, and 4 TB of pooled Ceph storage — with HA failover, replication factor 3, and the ability to lose an entire node without a single client AI Employee going offline. The 33 AI Employees we can run on this cluster today have access to more combined compute and RAM than all 15 of those VPS servers combined, at a higher spec per AI Employee, with full redundancy that no VPS plan can offer.
The economics flip as we scale >
At 15 AI Employees, VPS costs $3,057/year. At 33 — our current cluster capacity — equivalent VPS hosting would cost $6,727/year and still have no redundancy. Our on-site infrastructure carries zero incremental hosting cost per additional AI Employee. Every client we add beyond the break-even point is pure margin that stays in the business.
The infrastructure described in this document does not run itself. Behind every AI Employee deployment is a team of people who plan, build, manage, and continuously improve the systems that make it possible.
Jeff leads VA Staffer's overall strategy and is personally involved in every client engagement. On the infrastructure side, Jeff is responsible for the physical housing and management of the server equipment, onboarding new clients to the AI Employee platform, and the ongoing development of new skills and workflows that expand what AI Employees can do. He is also the primary architect of the service strategy — identifying where AI Employees create the most leverage for specific client roles and business types.
Jeff's direct involvement in both the technical and client-facing sides of the platform means the gap between what clients need and what the AI Employees deliver stays narrow. Strategy, service design, and infrastructure oversight all flow through the same person.
Brandon is the technical architect of the entire infrastructure. With over 20 years of professional experience in network engineering, Brandon designed the node and scale strategy that makes this cluster capable of growing predictably as VA Staffer's client base expands. He authored the installation and configuration scripts that allow new nodes to be provisioned reliably and repeatably — removing human error from a process that will be repeated multiple times as the cluster grows.
Brandon is also a planning and strategy partner on the infrastructure roadmap. The decisions documented in this report — the choice of hyperconverged architecture, the VLAN topology, the Ceph replication model, the stack-based expansion approach — reflect his engineering judgment built over two decades in the industry. When something needs to be built right and built to last, Brandon is the reason it is.
Jacklyn, Clarence, Liezele, and Julio form the core AI Employee operations team. Their work is the day-to-day engine that keeps client AI Employees performing at a high level. Collectively they are responsible for:
This team is what transforms the infrastructure from a technical system into a managed service. The hardware and software provide the foundation, but Jacklyn, Clarence, Liezele, and Julio are the people clients are ultimately relying on to make their AI Employees useful, reliable, and continuously improving.
VA Staffer's two-person web development team brings years of hands-on experience building websites, web applications, and digital assets for clients. That expertise is not going away. It is being redirected.
The reality of 2026 is that AI can now produce high-quality web development output — layouts, code, content, integrations — at a pace no individual developer can match working manually. VA Staffer recognized this early, and rather than treating it as a threat to the team, we treated it as an opportunity to multiply their value.
Our web development team is actively transitioning into AI training and upskilling roles. The knowledge they have built over years of client work — what makes a great landing page, how to structure a conversion flow, what clients in specific industries actually need from their web presence — is exactly the kind of deep domain knowledge that makes an AI Employee genuinely useful versus generically capable. By encoding that knowledge into skills, workflows, and AI Employee configurations, they are not just doing their job once. They are teaching the AI to do it thousands of times.
Multiplying human expertise through AI >
A skilled web developer who trains an AI Employee with their knowledge does not become less valuable. They become exponentially more productive. Every workflow they build, every skill they develop, every prompt they refine runs across every AI Employee deployment that uses it. Their years of expertise stop being limited by the hours in their day and start scaling with every new client we serve.
VA Staffer has invested in on-site infrastructure because the Managed AI Employee service we deliver to clients demands it. Cloud VPS hosting is convenient and low-barrier, but it cannot deliver the combination of dedicated performance, data sovereignty, long-term economics, and configurability that our clients' businesses deserve. Jeff J Hunter and Brandon at Belew Consulting designed this infrastructure specifically to give AI Employees the dedicated, secure, and scalable foundation they need to perform reliably for every client we serve.
The 3-node Phase 1 cluster gives us a production-grade foundation today. The path to Phase 2 is clearly defined, low-risk, and additive. Every dollar invested in this infrastructure is infrastructure we own, control, and that directly serves our clients rather than enriching a hosting provider. Behind it is a team that knows how to run it, grow it, and keep it working for the businesses depending on it.
Our commitment to every client >
Every AI Employee we deploy for a client runs on hardware we own and manage, not a shared VPS account that could be throttled, breached, or shut down at a third party's discretion. This infrastructure is why our Managed AI Employee service can make promises that generic hosted AI tools cannot: dedicated performance, genuine data security, and a platform built to grow with your business. That is the foundation Jeff J Hunter and Brandon built, and it is the foundation every client's AI Employee runs on.
*VA Staffer · Confidential · March 2026*